

AoAD2 Practice: Capacity

This is an excerpt from The Art of Agile Development, Second Edition. Visit the Second Edition home page for additional excerpts and more!
This excerpt is copyright 2007, 2021 by James Shore and Shane Warden. Although you are welcome to share this link, do not distribute or republish the content without James Shore’s express written permission.
Capacity
- Audience
- Developers
We know how much work we can sign up for.
Teams using iterations are supposed to finish every story in every iteration. But how do they know how much to sign up for? That’s where capacity comes in. Capacity is a prediction of how much the team can reliably accomplish in a single iteration.
Capacity is only for predicting what you can include in your next iteration. If you need to predict when a particular set of stories will be released, see the “Forecasting” practice instead.
If you’re using continuous flow rather than iterations, you don’t need to worry about capacity. You’ll just start new stories when the previous ones are finished.
Capacity was originally called velocity. I don’t use that term anymore because “velocity” implies a level of control that doesn’t exist. Think of a car: it’s easy to increase the velocity; just press the gas pedal. But if you want to increase the car’s capacity, you need to make much more drastic changes. Team capacity is the same. It’s not easily changed.
Yesterday’s Weather
When teams are pressured to commit to more than they can deliver, everyone loses.
Capacity can be a contentious topic. Customers want the team to deliver more every week. Developers don’t want to be rushed or pressured. Because customers often have the ear of the team’s sponsor, they tend to win...in the short term. In the long-term, when teams are pressured to commit to more than they can deliver, everyone loses. Reality prevails and development ends up taking longer than expected.
To avoid these problems, measure your capacity. Don’t guess. Don’t hope. Just measure. It’s easy: you’ll probably get the same amount done this week that you did last week. This is also known as yesterday’s weather, because you can predict today’s weather by saying it’s likely to be the same as yesterday’s.
More specifically, your capacity is the number of stories that you started and completely finished in the previous iteration. Partially done stories don’t count. For example, if you started seven stories last iteration and finished six of them, your capacity is six, and you can choose six stories next iteration.
Don’t average multiple iterations. Just use the previous iteration. The “Stabilizing Capacity” section explains how to create a stable capacity without averaging.
Counting stories works only if your stories are about the same size. You can split and combine stories to get the size “just right,” as described in the “Splitting and Combining Stories” section. Over time, your team will learn how to make stories the same size.
Your stories probably won’t all be the same size at first. In that case, you can estimate your stories instead, as I’ll describe in the “Estimating Stories” section. To measure your capacity when using estimates, look at the stories you started and completely finished during the last iteration. Add up their estimates. That’s your capacity.
For example, if you finished six of the stories you started last iteration, and their estimates were “1, 3, 2, 2, 1, 3,” your capacity is 1 + 3 + 2 + 2 + 1 + 3 = 12. Next iteration, you can choose any stories you like, as long as the total of their estimates is 12.
Yesterday’s Weather is a simple yet surprisingly sophisticated tool. It’s a feedback loop, which leads to a magical effect: if your team underestimates its workload, and is unable to finish all of its stories by the iteration deadline, your capacity decreases, and you sign up for less work next time. If you overestimate your workload and finish early, your team takes on more stories, its capacity increases, and you sign up for more work.
- Ally
- Slack
It’s an extremely effective way of balancing the team’s workload. Combined with slack, capacity allows you to reliably predict how much you can finish in every iteration.
Capacity and the Iteration Timebox
Yesterday’s Weather relies upon a strict iteration timebox. To make capacity work, never count stories that aren’t “done done” by the end of the iteration. Never allow the iteration deadline to slip, even by a few hours.
Artificially increasing your capacity number will just make it harder to meet commitments.
You may be tempted to cheat a bit and delay the iteration deadline, or count a story that’s almost done. Don’t! It will increase your capacity number, sure, but it will disrupt the feedback loop. You’ll sign up for more than your team can actually accomplish, amplifying the problem for next time and making it even harder to meet your commitments.
One project manager I worked with wanted to add a few days to the beginning of an iteration so his team could “hit the ground running” and he could have a more impressive capacity number to share with his manager. By doing so, he set his team up for failure: it couldn’t keep up the pace in the following iteration. Remember that capacity is for predicting how much you can fit in an iteration. It doesn’t represent productivity.
Capacity tends to be unstable when teams first form and when they’re first learning to be Agile. Give it three or four iterations to stabilize. After that point, you should have the same capacity every iteration, unless there’s a holiday. Use your iteration slack to ensure that you consistently finish every story. If the team’s capacity changes more than once or twice per quarter, look for deeper problems, and consider asking a mentor for help.
Stabilizing Capacity
- Ally
- Done Done
Whenever your team fails to finish everything it had planned, your capacity should go down. This will give you more time to finish your work in the next iteration, which will cause your capacity to stabilize at the new, lower level.
But how does your capacity go back up? Counterintuitively, you should be quick to decrease your capacity and slow to increase it. Increase your capacity only when you not only finish all the stories you had planned, but you also had time to clean as you go: you cleaned up rough spots in the code you touched, improved automation and infrastructure, and took care of other important, nonurgent tasks related to the stories you worked on.
Increase capacity only when you have enough time to clean as you go.
If you had enough time to clean as you go, you can take on an additional story. If you finish it before the end of the iteration, your capacity will go up.
I work with a lot of teams, and one of the most common problems I see is excessive schedule pressure. Excessive schedule pressure universally reduces teams’ performance. It causes them to rush, take shortcuts, and make mistakes. Those shortcuts and mistakes hurt their internal quality—code, automation, and infrastructure quality—and that poor quality causes everything to take longer, ironically giving them less time to do their work. It’s a vicious cycle that further increases schedule pressure and decreases performance.
The most effective way to improve the performance of teams in this situation is to reduce their schedule pressure. Capacity will do this automatically, if you let it. The “Stabilizing Capacity” figure illustrates how.
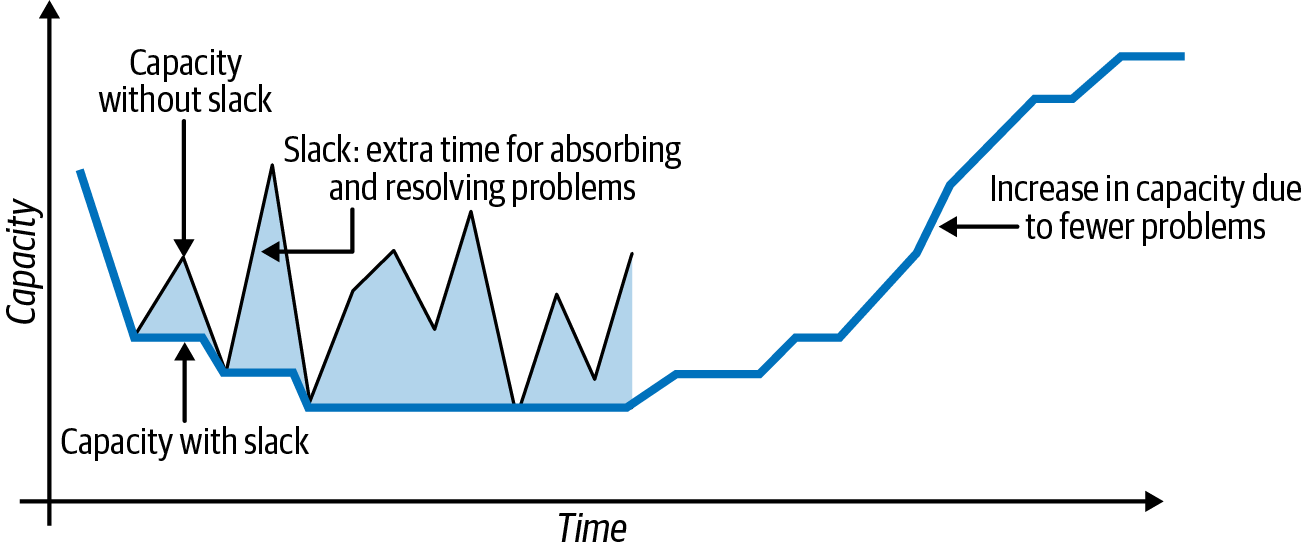
Figure 1. Stabilizing capacity
The thin, jagged line shows the team’s “high pressure” capacity. This is its capacity if team members rush as fast as they can. You can see that it’s highly variable. Some weeks, everything goes smoothly. Other weeks, they run into bugs and internal quality problems.
The thick, smooth line shows the team’s “low pressure” capacity. This is the result of following the “be fast to decrease and slow to increase” rule. You can see that, whenever the team failed to deliver everything planned, team members decreased the team's capacity, and they didn’t increase it again for quite some time.
- Ally
- Slack
The shaded peaks represent the team’s slack: the difference between its “low pressure” capacity and the amount of time it needed to finish its stories. Some weeks, they had a lot of slack. Others, very little. When the team has a lot of slack, team members use it to improve internal quality and address issues that slow them down.
Over time, that extra effort builds up. Because team members aren't rushing as fast as they can, they gradually improve their internal quality and fix problems. Eventually, they feel relaxed, in control, and in possession of more time than they need for cleanup. That’s when they increase their capacity. The result is better capacity, and more enjoyable work, than that of teams that rush as fast as they can.
Slack is your best option for improving how much work your team can do.
This graph illustrates my actual experience, not some abstract theory. I’ve seen variations on this theme play out, on real teams, time and time again. It can be hard to stabilize your capacity when your team is under a lot of pressure, but it’s worth it. It’s your best option for actually improving the amount of work your team can do.
Why Estimate Accuracy Doesn’t Matter
Capacity automatically adjusts for inaccurate estimates. Here’s how it works:
Suppose your team has 30 person-days per iteration. To simplify the example, assume the team's stories are all estimated at three days each. If the estimates are perfectly accurate, the team should be able to finish 10 stories per iteration (30 person-days per iteration ÷ 3 estimated days per story).
But it turns out that their estimates are not perfectly accurate! In fact, they’re not even close. It actually takes the team six person-days to finish each story, not three. At the end of the iteration, it finished only five stories (30 person-days per iteration ÷ 6 days per story).
The team's measured capacity is 15: team members finished five stories estimated at three days each. So, next iteration, they can sign up for only five stories (15 capacity ÷ 3 estimated days per story). And even though their estimates are completely wrong, they finish every single one (30 person-days ÷ 6 days = 5 stories).
These calculations are just so you can understand the feedback loop. You don’t need to perform any calculations in the real world. Capacity and slack together are remarkably simple and resilient. Just stabilize your capacity as I’ve described and it will all work out.
Estimating Stories
Yesterday’s Weather depends on consistency, but your team may have trouble creating consistently sized stories. That’s okay. You can use estimates instead.
As the sidebar discusses, it doesn’t matter how accurate your estimates are, as long as they’re consistent. That’s a good thing, because programmers tend to be terrible at estimating. One team I worked with measured the actual time its stories took. We did this for 18 months. The estimates were never accurate: the team averaged about 60% of the actual time required.
But you know what? It didn’t matter, because the team's estimates were consistent, at least in aggregate. That team had a stable capacity and consistently finished every story for months on end.
So, to estimate your stories, don’t worry about accuracy. Just focus on consistency. Here’s how:
Estimate only the constraint. One type of work—typically programming—will be the bottleneck for your team. Estimate all your stories in terms of that work only, because your constraint determines your schedule. There will be occasional exceptions, but they’ll be absorbed by your iteration slack.
Let experts estimate. How long do the team members who are most qualified to do the work think the story will take?
Estimate in “ideal” hours or days. How long will the story take if one of your most qualified team members does it, they experience no interruptions, can ask questions of anyone else on the team, don’t have to wait for people outside the team, and everything goes well?
Think of tasks. If you’re having trouble estimating, mentally break the story down into the tasks it involves, then add up the time required for each one.
Round into three “buckets.” Anything larger needs to be split; anything smaller needs to be combined. To choose your buckets, divide your capacity by 12, then multiply by 2 and 3. Tweak the results as needed. For example, if your capacity is between 9 and 14, then your buckets should be 1, 2, and 3. If it’s between 3 and 8, your buckets should be ½, 1, and 1½. The goal is to have at least four stories per iteration and six on average.
This approach will give you an estimate in ideal hours or days. The real work will take much longer, but that doesn’t matter: you’re going for consistency, not accuracy. To avoid people accidentally interpreting your estimate as a commitment, call the number “points,” not “hours” or “days.”
Once you’ve had some experience, these techniques work even better:
Match other stories. What did you say for other stories like this one? Use the same estimate.
Compare to other stories. Is this story about twice as much work, or half as much, as another story? Use double or half the estimate.
Go with your gut. Use whatever number feels right.
I have two types of estimating sessions you can use: conversational estimating and affinity estimating. In either case, involve everybody who’s qualified to do the work (the “estimators”) and at least one on-site customer. Other team members are also welcome—the discussions can be informative—but they aren’t required.
A Conversational Estimate
The team has gathered to estimate stories. Elissa, one of the on-site customers, starts the discussion. Kenna, Inga, and Austin are all programmers.
Elissa: Here’s our next story. [She reads the story aloud, then puts it on the table.] “Report on parts inventory in warehouse.”
Kenna: This is part of the inventory discrepancy effort, right? [Elissa nods.] We’ve done so many reports by now that a new one shouldn’t be too much trouble. They’re typically one point each. We already track parts inventory, so there’s no new data for us to manage. Is there anything unusual about this report?
Elissa: I don’t think so. We put together a mock-up. [She pulls out a printout and hands it to Kenna.]
Kenna: This looks pretty straightforward. [She puts the paper on the table. The other programmers take a look.]
Inga: Elissa, what’s this “age” column you have here? I didn’t think age related to the inventory discrepancies.
Elissa: It doesn’t relate, exactly. That’s the number of business days since the part entered the warehouse. We thought it would be useful in the future.
Inga: You need business days, not calendar days?
Elissa: That’s right.
Inga: What about holidays?
Elissa: We only want to count days that we’re actually in operation. No weekends, holidays, or scheduled shutdowns.
Austin: Inga, I see what you’re getting at. Elissa, we have the date the part entered the warehouse, but we don't currently track scheduled shutdowns. We would need a new UI, or a data feed, to know that information. It could add to the complexity of the admin screens, and you and Bradford have said that ease of admin is important to you. Can we report it in calendar days instead?
Elissa: Hmm. The exact number isn’t important, but people think in terms of business days, and if we’re going to provide a piece of information, I would prefer it to be accurate. What about holidays—can you do that?
Inga: Can we assume that the holidays will be the same every year?
Elissa: Not necessarily, but they won’t change very often.
Inga: Okay, then we can put them in the config file for now rather than creating a UI for them. That would make this cheaper.
Elissa: You know, I’m going to save this for later. This field isn’t our focus and I don’t think it’s going to be worth the added cost. Let’s leave it out for now. I’ll make a separate story for it. [She takes a card and writes, “Add ‘age’ column to part inventory report.”]
Austin: Sounds good. This report should be pretty easy, then. Does it need a UI?
Elissa: All we need to do is add it to the list of reports on the reporting screen.
Inga: I think I’m ready to estimate. [Looks at other programmers.] This looks like a pretty standard report to me. It’s another specialization for our reporting layer with a few minor logic changes. I agree with Kenna. It’s one point.
[Austin nods.]
Kenna: One point. [She writes “1” on the story card.] Elissa, I don’t think we can estimate the “age” story until you know what kind of UI you want for it.
Elissa: That’s fair. [Adds a “Biz days? UI?” sticky note to the age card and sets it aside.] Our next story...
Conversational estimating
In conversational estimating, the team estimates one story at a time. It can be tedious, but it’s a good way to get everyone on the same page about what needs to be done.
An on-site customer starts each estimate by choosing a story and providing a brief explanation. Estimators can ask questions, but they should ask questions only if the answer would change their estimate. As soon as any estimator feels they have enough information, they suggest an estimate. Allow this to happen naturally—the person who is most comfortable should speak first, as this is often the person who’s most qualified to make the estimate.
If the suggested estimate doesn’t sound right, or if you don’t understand where it came from, ask for details. Alternatively, if you’re an estimator, provide your own estimate instead and explain your reasoning. The ensuing discussion will clarify the estimate. When the estimators are in agreement, write the estimate on the story card.
At first, different team members will have differing ideas of how long something should take. This will lead to inconsistent estimates. Talk it through, and if you can’t come to agreement, use the lowest estimate. (Remember, you need only consistency, not accuracy.) As your team continues to make estimates together, your estimates will synchronize, typically within three or four iterations.
If participants understand the stories and underlying technology, they should be able to estimate each story in less than a minute. If they need to discuss the technology, or ask questions of customers, then estimating may take longer. I look for ways to bring discussions to a close if an estimate takes longer than five minutes. If every story requires detailed discussion, something is wrong—see the “When Estimating Is Difficult” section.
Some people like to use planning poker1 for estimating. In planning poker, participants secretly choose a card with their estimate, reveal their estimates simultaneously, then discuss. It sounds fun, but it tends to result in a lot of unnecessary discussion. It’s useful if people are having trouble speaking up, but otherwise, it’s usually faster to just allow the person who’s most comfortable to speak first.
1Planning poker was invented by James Grenning in 2002 [Grenning2002] and was later popularized by Mike Cohn in [Cohn2005]. Cohn’s company, Mountain Goat Software, LLC, has trademarked the term.
Affinity estimating
Affinity estimating is a great technique for estimating a lot of stories quickly.2 It’s particularly useful when you have long planning horizons.
2Affinity estimating was invented by Lowell Lindstrom in the early days of Extreme Programming.
Affinity estimating is a variant of mute mapping (see the “Work Simultaneously” section). An on-site customer puts a pile of story cards to estimate on a table or virtual whiteboard. One end is identified as “smallest” and the other end is identified as “largest.” Then estimators arrange the story cards along that spectrum, grouping them into clusters of similar size. Cards that need additional clarification from customers go into a separate cluster off to the side, as do cards that need a spike story (see the “Spike Stories” section).
All this work is done silently. Estimators can move cards if they disagree with where they’re placed, but they can’t discuss them. Doing the work silently avoids the sidetracking that tends to occur when discussing estimates. As a result, estimate mapping is very fast. One person told me their team estimated 60 stories in 45 minutes the first time they tried it.
After all the stories are grouped, the team labels each cluster with an estimate. The actual numbers aren’t important, as long as their relative sizes are correct. In other words, a story in a cluster labeled “2” should take about twice as long as a story in a cluster labeled “1.” For consistency with conversational estimates, though, it can be useful to estimate in ideal hours or days. Estimating the clusters should take only a minute or two.
Finally, choose three clusters that match your estimate “buckets” (described previously). For example, if your capacity is 15, you’d choose the clusters estimated at 1, 2, and 3. The stories in larger clusters will need to be split, and the stories in smaller clusters will need to be combined.
The cards in your final three buckets are good to go. Write their estimate on each one. The remaining cards need to be split, combined, discussed, or spiked, depending on which cluster they’re in. That can be done simultaneously, followed by another estimating mapping session, or it can be done one at a time using conversational estimating.
When Estimating Is Difficult
When your team first forms, estimating will probably be somewhat slow and painful. It gets better with practice.
One common cause of slow estimation is inadequate preparation by on-site customers. At first, estimators are likely to ask questions that customers haven’t considered. In some cases, customers will disagree on the answer and need to work it out.
A customer huddle—in which the customers briefly discuss the issue, come to a decision, and return—is one way to handle this. While they huddle, estimators continue estimating stories they already understand.
Another option is to put the question on a sticky note and attach it to the card. The customers take the card and work out the details at their own pace, then bring it back for estimating in a later session.
Developer inexperience can also lead to slow estimation. If estimators don’t understand the stories well, they will need to ask a lot of questions before they can make an estimate. If they don’t understand the technology, though, just create a spike story (see the “Spike Stories” section) and move on.
Some estimators try to figure out all details of a story before making an estimate. Remember that the only details that matter, during estimating, are the ones that would put the estimate in a different bucket. Focus on the details that would change the estimate and save the rest for later.
This sort of over-attention to detail sometimes occurs when an estimator is reluctant to make estimates. It’s common among programmers who’ve had their estimates used against them in the past. They’ll try to make their estimates perfectly accurate, rather than aiming for consistency that’s “good enough.”
Estimator reluctance can be a sign of organizational difficulties or excessive schedule pressure, or it may stem from past experiences that have nothing to do with the current team. In the latter case, estimators usually come to trust the team over time.
To help address these issues during estimation, you can ask leading questions. For example:
Customers having trouble: Do we need a customer huddle on this question? Should we put this question on the story and come back to it later?
Estimators uncertain about technology: Should we make a spike story for this one?
Estimators asking a lot of questions: Do we have enough information to estimate this story? Will the answer to that question change your estimate?
A story taking more than five minutes: Should we come back to this story later?
Defending Estimates
It’s almost a law of nature: on-site customers and stakeholders are invariably disappointed with their teams’ capacity. Sometimes they express their disappointment in disrepectful ways. Team members with good social skills can help defuse the situation. Often, the best approach is to ignore people’s tone and treat comments as straightforward requests for information.
In fact, a certain amount of back-and-forth is healthy. As the “How to Win the Planning Game” section discusses, questions about estimates can lead to better stories that focus on the high-value, low-cost aspects of customers’ ideas.
Politely and firmly refuse to change your estimates when pressured.
Be careful, though: questions can cause estimators to doubt their estimates. Developers, your estimates are likely correct, or at least consistent, which is what really matters. Change your estimate only if you learn something genuinely new. Don’t change it just because you feel pressured. You’re the ones who will be implementing the stories, and you’re the ones most qualified to make estimates. Be polite, but firm:
I’m sorry you don’t like these estimates. We believe they’re correct, but if they’re too pessimistic, our capacity will automatically increase to compensate. We have a professional obligation to you and to this organization to give you the best estimates we know how, even if they’re disappointing, and that’s what we’re doing.
If a stakeholder reacts with disbelief or browbeats you, they may not realize how disrepectful they’re being. Sometimes making them aware of their behavior can help:
I’m getting the impression you don’t respect or trust our professionalism. Is that what you intended?
- Ally
- Roadmaps
Stakeholders may also be confused by the idea of estimating in points. I tend to avoid sharing capacity and estimates outside the team for that reason. I report the stories and increments we’re working on instead. But if an explanation is needed, I start with a simplified explanation:
A point is an estimation technique that focuses on consistency. It allows us to make short-term predictions based on measured results. Our measured capacity is 12 points, which means we finished 12 points of work last week. Therefore, we predict that we can finish 12 points of work this week.
Sometimes, people will argue against measuring capacity. “If your team has six programmers and there are five days in an iteration, shouldn’t your capacity be 30 points?” You can try to explain how ideal time estimates work, but that has never worked for me. Now I just offer to provide detailed information:
Capacity is based on measurements and is expected to be lower than person-days. If you like, we can perform a detailed audit of our work next week and tell you exactly where the time is going. Would that be helpful?
Your interlocutor will usually back off at this point, but if they say “yes,” go ahead and track everyone’s time in detail for a week. It’s annoying, but should defuse concerns, and you can use the same report again the next time someone asks.
- Ally
- Stakeholder Trust
These sorts of questions tend to dissipate as stakeholders gain trust in the team’s ability to deliver. If they don’t, or if the lack of trust is particularly bad, ask your manager or a mentor for help.
Your Initial Capacity
When you plan your first iteration, you won’t have any history, so you won’t have a capacity or estimate buckets.
Partially done work is never counted.
Start out by using one-week iterations and estimate buckets of ½ day, 1 day, and 1½ days. Work on one or two stories at a time, as the “Your First Week” section discusses. At the end of the first iteration, you’ll have a capacity you can use for your next iteration. Remember not to count stories that weren’t complete. Throw them away and make new stories, with new estimates, representing the amount of work that remains. (Yes, that means you won’t count the partially done work. Partially done work is never counted.)
If you got less than four stories done, cut the estimate buckets in half (use two-, four-, and six-hour buckets) for your next iteration. If you got more than 12 stories done, double the buckets (one, two, and three days). Continue in this way until your capacity stabilizes.
Your capacity should stabilize after about four iterations. With more experience, you’ll eventually be able to size stories so you finish the same number every iteration. When that becomes second nature, you can stop estimating entirely and just count stories. But you’ll still need to talk stories over with customers to make sure they’re the right size.
How to Improve Capacity
Stakeholders always want more capacity. It is possible...but it isn’t free. You have multiple options:
Improve internal quality
The most common capacity problem I see is poor internal quality: crufty code, slow and unreliable tests, poor automation, and flaky infrastructure. It’s also called technical debt.
Internal quality has a greater impact on team capacity than any other factor. Make it a priority and your capacity will improve dramatically. However, this isn’t a quick fix. Teams with internal quality problems often have months, or even years, of cleanup ahead of them.
- Ally
- Slack
Rather than stopping work to fix the problems, improve quality incrementally, using slack, as described in the “Stabilizing Capacity” section. Establish a habit of continuously improving everything you touch. Be patient: although you should see a morale increase almost immediately, you may not see an improvement in capacity for several months.
Improve customer skills
- Ally
- Whole Team
If your team doesn’t include on-site customers, or if they aren’t available to answer questions when developers need them, developers have to either wait or make guesses about the answers. Both of these reduce capacity. Improving developers’ customer skills can reduce their reliance on on-site customers.
Support energized work
- Ally
- Energized Work
Tired, burned-out developers make costly mistakes and don’t put forth their full effort. If your organization has been putting a lot of pressure on the team, or if developers have worked a lot of extra hours, shield them from organizational pressure and consider instituting a no-overtime policy.
Offload duties
The team members who can work on the constraint—often, it’s programmers—should hand off any work that others can do. Find ways to excuse them from unnecessary meetings, shield them from interruptions, and have somebody else take care of organizational bureaucracy such as time sheets and expense reports. You could even assign an assistant to the team.
Support the constraint
People who can’t contribute to constraint-related tasks will have some discretionary time available. Although they should make sure that people who do work on the constraint never have to wait for them, they shouldn’t work too far ahead. That will just create extra work-in-progress inventory. (See the “Key Idea: Minimize Work in Progress” sidebar.)
Use your extra time to reduce the burden on the constraint.
Instead, use the extra time to reduce the burden on the constraint. A classic example is testing. Some teams need so much manual testing that the final days of every iteration are dedicated to testing the software. Rather than moving on to the next set of features, programmers can use that time to write automated tests and reduce the testing burden.
Provide needed resources
Most teams have all the resources they need. (Remember, “resources” refers to equipment and services, not people.) However, if team members complain about slow computers, insufficient RAM, or inappropriate tools, get those resources for them. It’s always surprising when a company nickle-and-dimes its software teams. Does it make sense to save $5,000 in equipment costs if it costs everyone half an hour per day? A team of six people will recoup that cost within a month. And what about the opportunity costs of releasing more slowly?
Add people (carefully)
- Allies
- Pair Programming
- Mob Programming
- Collective Code Ownership
- Team Room
Capacity is related to the number of people who can work on your team’s constraint, but unless your team is woefully understaffed and experienced personnel are readily available, adding people won’t make an immediate difference. As [Brooks1995] famously said, “Adding people to a late project only makes it later.” Expect new team members to take a month or two to be productive. Close collaboration can help reduce that time.
Likewise, adding people to large teams can cause communication challenges that decrease productivity. Six programmers is my preferred number for teams using pair programming, and I readily add good programmers to reach that point. Past six, I’m cautious about adding programmers and increase past eight only on rare occasions. Other skills are proportional, as the “Whole Team” practice describes.
Capacity Is Not Productivity
Capacity is a prediction tool, not a productivity measure.
One of the most common mistakes I see organizations make is to confuse capacity with productivity. Let me be clear: capacity isn’t a measure of productivity. It’s a prediction tool. It’s influenced by productivity changes, sure, but it doesn’t measure them, and even then, the relationship is tenuous. In particular, capacity can’t be compared across teams.
The capacity number is an amalgamation of many factors: The number of people working on the constraint. The number of hours they work. The ratio of their estimates to actual time. Their software’s internal quality. The amount of time they spend waiting for people. The amount of time they spend on organizational overhead. The number of shortcuts they take. The amount of slack they have.
These factors are different for every team, so you can’t use capacity to compare two teams. If one team has twice the capacity number of another, it could mean that it has less overhead...but it’s more likely that it just has a different approach to estimating.
Teams also don’t have control over most of the things that affect capacity. In the short term, they can control only the number of hours they work and the number of shortcuts they take. So a team that’s judged on its capacity can respond to that pressure only by working extra hours, doing sloppy work, or cutting its slack. That may lead to a short-term boost in its capacity numbers, but it will reduce the team's actual ability to deliver.
Don’t share capacity numbers outside the team. If you’re a manager, don’t track, reward, or even talk about capacity, other than to encourage a stable capacity. And never, ever call it productivity.
To understand what to do instead, see the “Management” practice.
Cargo Cult: Gotta Go Fast
“You need to go faster!” Beckie barks. She’s your manager’s manager. “Silva’s team has twice your capacity. It’s not okay for you to be half as productive as them.”
“Okay...” you say, fighting down your urge to engage in a Career Limiting Move. “First, Silva’s team is doing different work than we are, so the capacity numbers aren’t comparable. Second,” you make an effort at a smile, “I’d love to increase our capacity. The biggest thing holding us back is a lack of access to Christiane. She doesn’t want us to talk to stakeholders ourselves, but she isn’t available to participate in our planning sessions. We keep having to redo our work.”
“Oh, no you don’t.” Beckie’s not having it. “She’s busy. You’re Agile. That means you have ownership, right? You fix it.”
Career Limiting Moves aren’t really so bad, are they? Luckily, your manager, Darryl, comes around the corner.
“Beckie! So good to see you. I overheard what you said about Christiane, and I had a great idea. You’re right about ownership. Why don’t we take some work off of Christiane’s plate? We’ll take care of talking to our stakeholders, and she’ll be freed up to focus on...” Darryl moves off, taking Beckie with him, and you sigh in relief. You’re glad you have Darryl to manage Beckie’s demands.
Or you could just fake a higher capacity. Multiplying all your estimates by three should do the trick.

Questions
How should we count partially done stories?
Partially done stories don’t count. At the end of the iteration, if you have any partially done stories, create a new story for the work remaining and give it a new estimate, if you’re using estimates. (See the “Incomplete Stories” section for details.) The part done in this iteration doesn’t count toward your capacity, which means your capacity will go down.
This may sound harsh, but if you’re using iterations, capacity, and slack correctly, partially done stories should be extremely rare. If you have partially done stories, something has gone wrong. Reducing your capacity will give your team the slack you need to resolve the problem.
How do we change our capacity if we add or remove people?
If you add or remove only one person, try leaving your capacity unchanged and see what happens. Another option is to adjust your capacity proportionally to the change. Either way, your capacity will adjust to the correct number after another iteration.
How can we have a stable capacity? People take vacations, get sick, and so on.
Your iteration slack should handle minor variations in people’s availability. If a large percentage of the team is away, as during a holiday, your capacity may go down for an iteration. This is normal. You can reset it in the next iteration.
If you have a small team, you might find that even one day of absence is enough to destabilize your capacity. In this case, you may wish to use two-week iterations. See the “Iterations” section for a discussion of the trade-offs.
Isn’t it a waste of time for everyone to estimate stories together?
It does take a lot of time for people to estimate together, but this isn’t wasted time. Estimating sessions aren’t just for estimation—they’re also a crucial first step in communicating and clarifying what needs to be done. Developers ask questions and clarify details, which often leads to ideas on-site customers haven’t considered. Sometimes this collaboration reduces overall cost, as the “How to Win the Planning Game” section describes.
All the developers need to be present to ensure they understand what they will be building. Having them estimate together also improves consistency.
Isn’t it risky to estimate based on the most-qualified team member? Shouldn’t we use the average team member, or least-qualified for extra safety?
The “Yesterday’s Weather” feedback loop eliminates the need for estimate accuracy, as the “Why Estimate Accuracy Doesn’t Matter” sidebar describes, so they’re all equally safe. What’s important is consistency, and thinking in terms of ideal time and the most-qualified team member is the easiest way to be consistent.
When should we re-estimate our stories?
Because story estimates need to be consistent with each other, you shouldn’t re-estimate stories unless their scope changes. Even then, don’t re-estimate stories after you’ve started working on them, because you’ll know too many implementation details to make a consistent estimate.
On the other hand, if your constraint changes and different people start making estimates, both your estimates and capacity have to start over from scratch.
To make our estimates, we made some assumptions about the technical design. What if the design changes?
Agile assumes you’re building your design incrementally and improving the whole design over time. As a result, your estimates will usually remain consistent with each other.
How do we deal with technical dependencies in our stories?
With proper incremental design, technical dependencies should be rare, although they can happen. I typically make a note along with the estimate: “6 (4 if story Foo done first).”
- Ally
- Incremental Design
If you find yourself making more than a few of these notes, something is wrong with your approach to incremental design. Evolutionary design can help, and consider asking a mentor for help.
Prerequisites
- Allies
- Task Planning
- Slack
- Stakeholder Trust
Capacity assumes the use of iterations and requires slack to smooth out minor problems and inconsistencies.
Estimating requires trust: developers need to believe they can give accurate estimates without being attacked, and customers and stakeholders need to believe the developers are providing honest estimates. That trust often isn’t present at first, and if it isn’t, you need to work on developing it.
Regardless of your approach to estimating and capacity, never use capacity numbers or incorrect estimates to attack developers. This is a quick and easy way to destroy trust.
Indicators
When you use capacity well:
Your capacity is consistent and predictable each iteration.
You make iteration commitments and meet them reliably.
Estimation is fast and easy, or not required at all.
You can size most stories in a minute or two.
Alternatives and Experiments
The central idea of capacity is Yesterday’s Weather: focusing on consistency, rather than accuracy; basing predictions on past measurements; and using that to create a feedback loop that automatically corrects itself.
- Ally
- Slack
There are countless approaches to estimation and prediction. Yesterday’s Weather has the advantage of being simple and reliable. It’s not perfect, though, and relies on slack to cover its imperfections. Other approaches add a lot complexity in an effort to be more precise. Despite that added complexity, I’ve yet to see any come close to working as well as the Yesterday’s Weather + Slack feedback loop.
You’re welcome to experiment with better ways of determining capacity, but don’t do it right away. First, learn how to use this book’s approach to reliably finish iterations, and stick with it for several months. The ripple effects of changing capacity planning are profound, and hard to see without experience.
One of the most popular alternatives I see is to base capacity on the average of prior iterations, rather than just the past iteration. Another approach is to count stories that were started in one iteration and finished in another. I think both approaches are misguided: they’re both based on a desire to increase capacity, but they increase the capacity number without increasing the team’s actual ability to deliver. It just makes the team more likely to have trouble meeting their commitments. It’s better to bite the bullet, plan for a lower capacity, and use the resultant slack to increase the team’s actual, real-world ability to deliver.
Another popular alternative is the #NoEstimates movement, which sidesteps estimation entirely. There are two approaches to #NoEstimates, and I’ve included both in this book. The first is to count stories rather than estimate them, as described in this practice. Some teams use very small stories—more than a dozen per iteration—to help make that work. The second is to not use iterations at all, and instead use continuous flow, as described in the “Task Planning” practice. Both of these ideas are worth trying after you’ve mastered the basics.
Share your thoughts about this excerpt on the AoAD2 mailing list or Discord server. For videos and interviews regarding the book, see the book club archive.
For more excerpts from the book, see the Second Edition home page.